
2022
Geist, A. R., Fiene, J., Tashiro, N., Jia, Z., Trimpe, S.
The Wheelbot: A Jumping Reaction Wheel Unicycle
IEEE Robotics and Automation Letters, 7(4):9683-9690, IEEE, 2022 (article)

Bleher, S., Heim, S., Trimpe, S.
Learning Fast and Precise Pixel-to-Torque Control: A Platform for Reproducible Research of Learning on Hardware
IEEE Robotics & Automation Magazine, 29(2):75-84 , June 2022 (article)
2021
Fiedler, C., Scherer, C. W., Trimpe, S.
Learning-enhanced robust controller synthesis with rigorous statistical and control-theoretic guarantees
In 60th IEEE Conference on Decision and Control (CDC), IEEE, December 2021 (inproceedings) Accepted
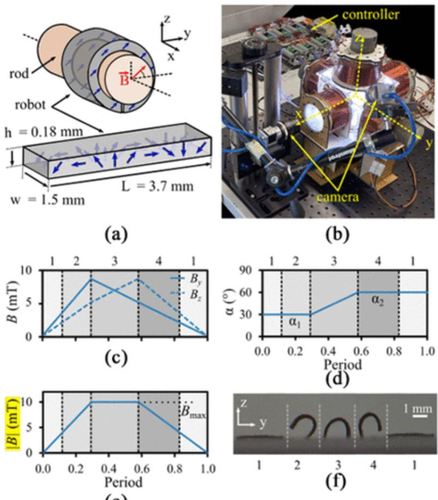
Demir, S. O., Culha, U., Karacakol, A. C., Pena-Francesch, A., Trimpe, S., Sitti, M.
Task space adaptation via the learning of gait controllers of magnetic soft millirobots
The International Journal of Robotics Research, 40(12-14):1331-1351, December 2021 (article)
Müller, S., von Rohr, A., Trimpe, S.
Local policy search with Bayesian optimization
In Advances in Neural Information Processing Systems 34, 25, pages: 20708-20720, (Editors: Ranzato, M. and Beygelzimer, A. and Dauphin, Y. and Liang, P. S. and Wortman Vaughan, J.), Curran Associates, Inc., Red Hook, NY, 35th Conference on Neural Information Processing Systems (NeurIPS 2021) , December 2021 (inproceedings)
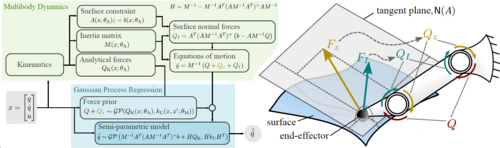
Rath, L., Geist, A. R., Trimpe, S.
Using Physics Knowledge for Learning Rigid-Body Forward Dynamics with Gaussian Process Force Priors
In Proceedings of the 5th Conference on Robot Learning, 164, pages: 101-111, Proceedings of Machine Learning Research, (Editors: Faust, Aleksandra and Hsu, David and Neumann, Gerhard), PMLR, 5th Conference on Robot Learning (CoRL 2021), November 2021 (inproceedings)
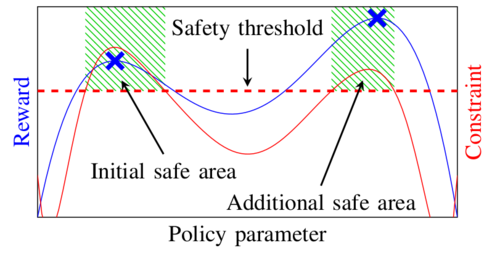
Baumann, D., Marco, A., Turchetta, M., Trimpe, S.
GoSafe: Globally Optimal Safe Robot Learning
In 2021 IEEE International Conference on Robotics and Automation (ICRA 2021), pages: 4452-4458, IEEE, Piscataway, NJ, IEEE International Conference on Robotics and Automation (ICRA 2021), October 2021 (inproceedings)
von Rohr, A., Neumann-Brosig, M., Trimpe, S.
Probabilistic robust linear quadratic regulators with Gaussian processes
Proceedings of the 3rd Conference on Learning for Dynamics and Control, pages: 324-335, Proceedings of Machine Learning Research (PMLR), Vol. 144, (Editors: Jadbabaie, Ali and Lygeros, John and Pappas, George J. and Parrilo, Pablo A. and Recht, Benjamin and Tomlin, Claire J. and Zeilinger, Melanie N.), PMLR, Brookline, MA 02446 , 3rd Annual Conference on Learning for Dynamics and Control (L4DC), June 2021 (conference)
Massiani, P., Heim, S., Trimpe, S.
On exploration requirements for learning safety constraints
In Proceedings of the 3rd Conference on Learning for Dynamics and Control, pages: 905-916, Proceedings of Machine Learning Research (PMLR), Vol. 144, (Editors: Jadbabaie, Ali and Lygeros, John and Pappas, George J. and Parrilo, Pablo A. and Recht, Benjamin and Tomlin, Claire J. and Zeilinger, Melanie), PMLR, 3rd Annual Conference on Learning for Dynamics and Control (L4DC), June 2021 (inproceedings)
Geist, A. R., Trimpe, S.
Structured learning of rigid-body dynamics: A survey and unified view from a robotics perspective
GAMM-Mitteilungen, 44(2):e202100009, Special Issue: Scientific Machine Learning, 2021 (article)
Fiedler, C., Scherer, C. W., Trimpe, S.
Practical and Rigorous Uncertainty Bounds for Gaussian Process Regression
In The Thirty-Fifth AAAI Conference on Artificial Intelligence, the Thirty-Third Conference on Innovative Applications of Artificial Intelligence, the Eleventh Symposium on Educational Advances in Artificial Intelligence, 8, pages: 7439-7447, AAAI Press, Palo Alto, CA, Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI 2021), Thirty-Third Conference on Innovative Applications of Artificial Intelligence (IAAI 2021), Eleventh Symposium on Educational Advances in Artificial Intelligence (EAAI 2021), May 2021 (inproceedings)
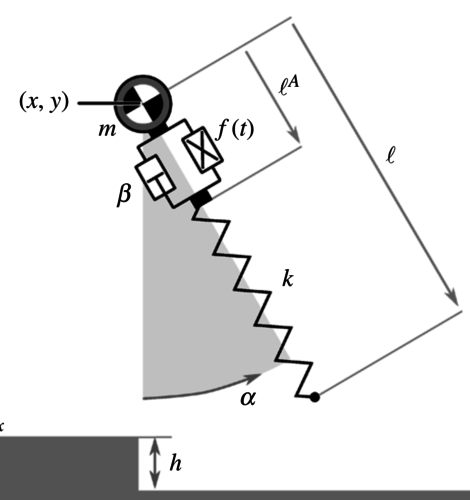
Heim, S., Millard, M., Mouel, C. L., Badri-Spröwitz, A.
A little damping goes a long way
In Integrative and Comparative Biology, 61(Supplement 1):E367-E367, Oxford University Press, Society for Integrative and Comparative Biology Annual Meeting (SICB Annual Meeting 2021) , March 2021 (inproceedings)
Marco, A., Baumann, D., Khadiv, M., Hennig, P., Righetti, L., Trimpe, S.
Robot Learning with Crash Constraints
IEEE Robotics and Automation Letters, 6(2):1439-1446, IEEE, February 2021 (article)
Buisson-Fenet, M., Morgenthaler, V., Trimpe, S., Di Meglio, F.
Joint State and Dynamics Estimation With High-Gain Observers and Gaussian Process Models
IEEE Control Systems Letters, 5(5):1627-1632, 2021 (article)
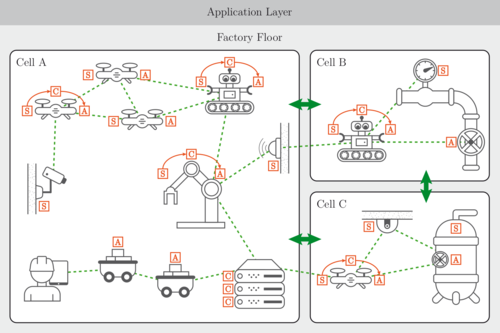
Baumann, D., Mager, F., Wetzker, U., Thiele, L., Zimmerling, M., Trimpe, S.
Wireless Control for Smart Manufacturing: Recent Approaches and Open Challenges
Proceedings of the IEEE, 109(4):441-467, 2021 (article)

Funk, N., Baumann, D., Berenz, V., Trimpe, S.
Learning Event-triggered Control from Data through Joint Optimization
IFAC Journal of Systems and Control, 16, pages: 100144, 2021 (article)
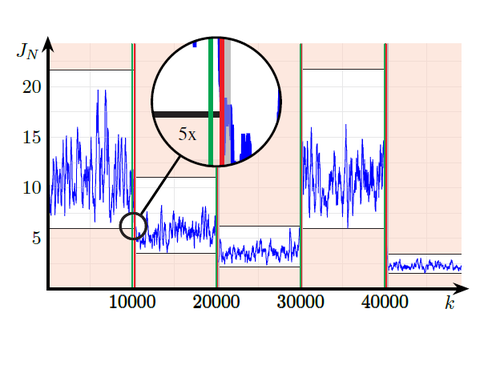
Schlüter, H., Solowjow, F., Trimpe, S.
Event-triggered Learning for Linear Quadratic Control
IEEE Transactions on Automatic Control, 66(10):4485-4498, 2021 (article)
Holicki, T., Scherer, C. W., Trimpe, J. S.
Controller Design via Experimental Exploration With Robustness Guarantees
IEEE Control Systems Letters, 5(2):641-646, 2021 (article)
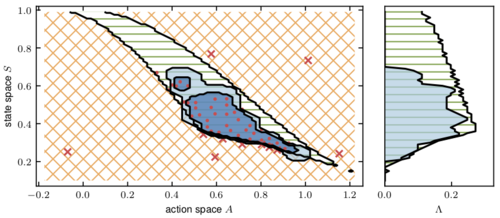
2020
Heim, S., Rohr, A. V., Trimpe, S., Badri-Spröwitz, A.
A Learnable Safety Measure
Proceedings of the Conference on Robot Learning, 100, pages: 627-639, Proceedings of Machine Learning Research, (Editors: Kaelbling, Leslie Pack and Kragic, Danica and Sugiura, Komei), PMLR, Conference on Robot Learning, October 2020 (article)
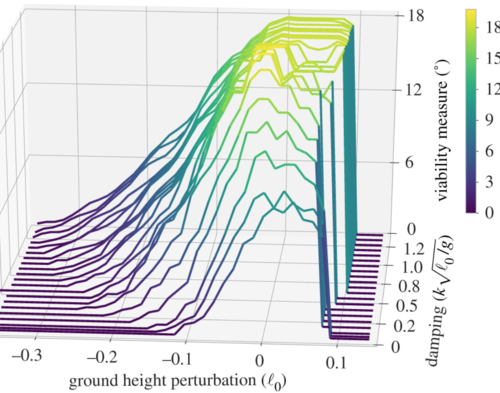
Heim, S., Millard, M., Le Mouel, C., Badri-Spröwitz, A.
A little damping goes a long way: a simulation study of how damping influences task-level stability in running
Biology Letters, 16(9):20200467, September 2020 (article)
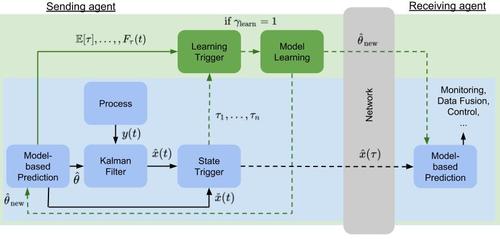
Solowjow, F., Trimpe, S.
Event-triggered Learning
Automatica, 117, pages: 109009, Elsevier, July 2020 (article)
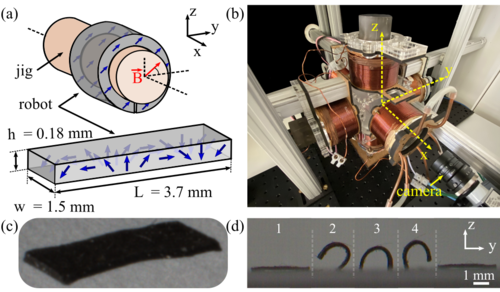
Culha, U., Demir, S. O., Trimpe, S., Sitti, M.
Learning of sub-optimal gait controllers for magnetic walking soft millirobots
In Robotics: Science and Systems XVI, pages: P070, (Editors: Toussaint, Marc and Bicchi, Antonio and Hermans, Tucker), RSS Foundation, Robotics: Science and Systems 2020 (RSS 2020), 2020 (inproceedings)
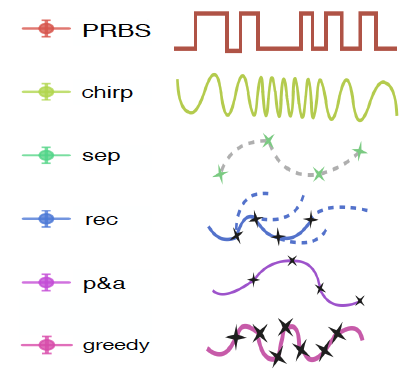
Buisson-Fenet, M., Solowjow, F., Trimpe, S.
Actively Learning Gaussian Process Dynamics
Proceedings of the 2nd Conference on Learning for Dynamics and Control, 120, pages: 5-15, Proceedings of Machine Learning Research (PMLR), (Editors: Bayen, Alexandre M. and Jadbabaie, Ali and Pappas, George and Parrilo, Pablo A. and Recht, Benjamin and Tomlin, Claire and Zeilinger, Melanie), PMLR, 2nd Annual Conference on Learning for Dynamics and Control (L4DC), June 2020 (conference)
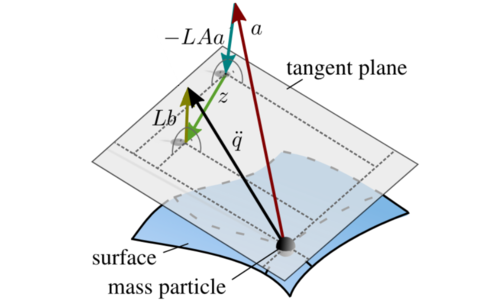
Geist, A. R., Trimpe, S.
Learning Constrained Dynamics with Gauss Principle adhering Gaussian Processes
In Proceedings of the 2nd Conference on Learning for Dynamics and Control, 120, pages: 225-234, Proceedings of Machine Learning Research (PMLR), (Editors: Bayen, Alexandre M. and Jadbabaie, Ali and Pappas, George and Parrilo, Pablo A. and Recht, Benjamin and Tomlin, Claire and Zeilinger, Melanie), PMLR, 2nd Annual Conference on Learning for Dynamics and Control (L4DC), June 2020 (inproceedings)
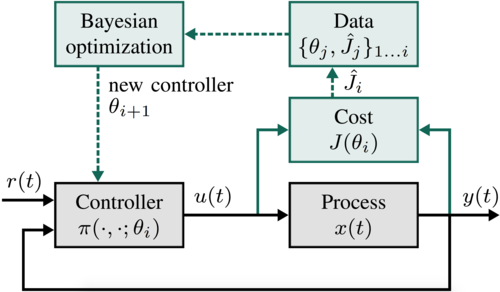
Neumann-Brosig, M., Marco, A., Schwarzmann, D., Trimpe, S.
Data-efficient Autotuning with Bayesian Optimization: An Industrial Control Study
IEEE Transactions on Control Systems Technology, 28(3):730-740, May 2020 (article)
Turchetta, M., Krause, A., Trimpe, S.
Robust Model-free Reinforcement Learning with Multi-objective Bayesian Optimization
In 2020 IEEE International Conference on Robotics and Automation (ICRA 2020), pages: 10702-10708, IEEE, Piscataway, NJ, IEEE International Conference on Robotics and Automation (ICRA 2020), May 2020 (inproceedings)
Lima, G. S., Trimpe, S., Bessa, W. M.
Sliding Mode Control with Gaussian Process Regression for Underwater Robots
Journal of Intelligent & Robotic Systems, 99(3-4):487-498, January 2020 (article)
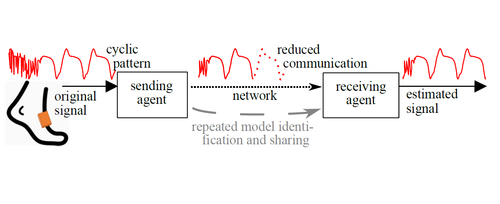
Beuchert, J., Solowjow, F., Raisch, J., Trimpe, S., Seel, T.
Hierarchical Event-triggered Learning for Cyclically Excited Systems with Application to Wireless Sensor Networks
IEEE Control Systems Letters, 4(1):103-108, January 2020 (article)
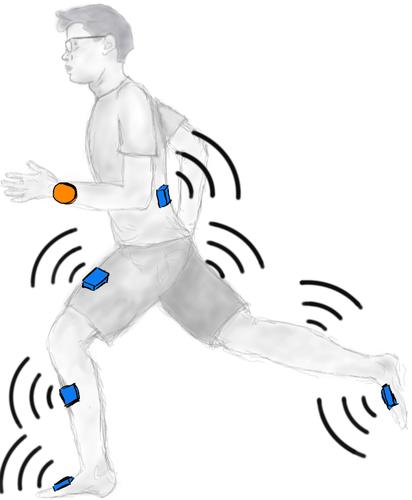
Beuchert, J., Solowjow, F., Trimpe, S., Seel, T.
Overcoming Bandwidth Limitations in Wireless Sensor Networks by Exploitation of Cyclic Signal Patterns: An Event-triggered Learning Approach
Sensors, 20(1):260, January 2020 (article)
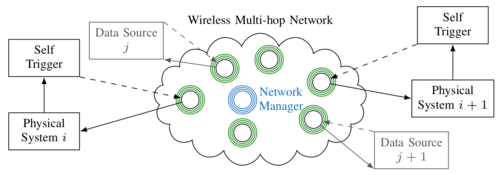
Baumann, D., Mager, F., Zimmerling, M., Trimpe, S.
Control-guided Communication: Efficient Resource Arbitration and Allocation in Multi-hop Wireless Control Systems
IEEE Control Systems Letters, 4(1):127-132, January 2020 (article)
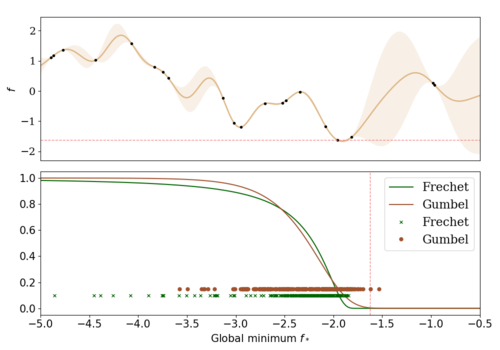
Marco, A., Rohr, A. V., Baumann, D., Hernández-Lobato, J. M., Trimpe, S.
Excursion Search for Constrained Bayesian Optimization under a Limited Budget of Failures
2020 (proceedings) In revision
Schwenkel, L., Gharbi, M., Trimpe, S., Ebenbauer, C.
Online learning with stability guarantees: A memory-based warm starting for real-time MPC
Automatica, 122, pages: 109247, 2020 (article)
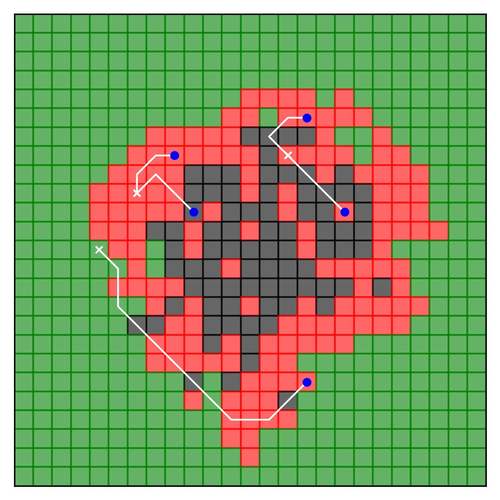
Haksar, R. N., Trimpe, S., Schwager, M.
Spatial Scheduling of Informative Meetings for Multi-Agent Persistent Coverage
IEEE Robotics and Automation Letters, 5(2):3027-3034, 2020 (article)
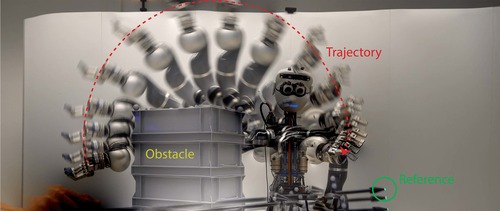
Nubert, J., Koehler, J., Berenz, V., Allgower, F., Trimpe, S.
Safe and Fast Tracking on a Robot Manipulator: Robust MPC and Neural Network Control
IEEE Robotics and Automation Letters, 5(2):3050-3057, 2020 (article)
2019
Haksar, R., Solowjow, F., Trimpe, S., Schwager, M.
Controlling Heterogeneous Stochastic Growth Processes on Lattices with Limited Resources
In Proceedings of the 58th IEEE International Conference on Decision and Control (CDC) , pages: 1315-1322, 58th IEEE International Conference on Decision and Control (CDC), December 2019 (conference)
Baumann, D., Mager, F., Jacob, R., Thiele, L., Zimmerling, M., Trimpe, S.
Fast Feedback Control over Multi-hop Wireless Networks with Mode Changes and Stability Guarantees
ACM Transactions on Cyber-Physical Systems, 4(2):18, November 2019 (article)
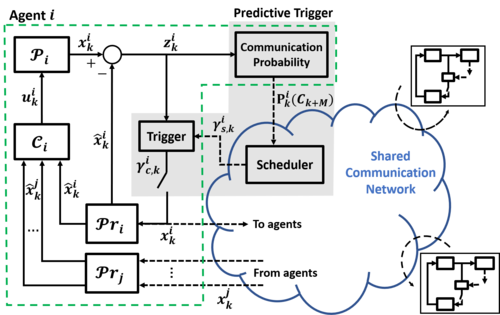
Mastrangelo, J. M., Baumann, D., Trimpe, S.
Predictive Triggering for Distributed Control of Resource Constrained Multi-agent Systems
In Proceedings of the 8th IFAC Workshop on Distributed Estimation and Control in Networked Systems, pages: 79-84, 8th IFAC Workshop on Distributed Estimation and Control in Networked Systems (NecSys), September 2019 (inproceedings)
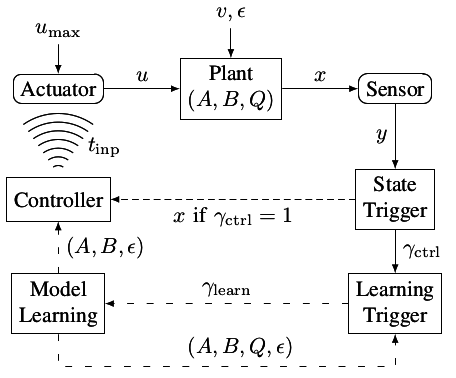
Baumann, D., Solowjow, F., Johansson, K. H., Trimpe, S.
Event-triggered Pulse Control with Model Learning (if Necessary)
In Proceedings of the American Control Conference, pages: 792-797, American Control Conference (ACC), July 2019 (inproceedings)
Romer, A., Trimpe, S., Allgöwer, F.
Data-driven inference of passivity properties via Gaussian process optimization
In Proceedings of the European Control Conference, European Control Conference (ECC), June 2019 (inproceedings)
Doerr, A., Volpp, M., Toussaint, M., Trimpe, S., Daniel, C.
Trajectory-Based Off-Policy Deep Reinforcement Learning
In Proceedings of the International Conference on Machine Learning (ICML), International Conference on Machine Learning (ICML), June 2019 (inproceedings)
Trimpe, S., Baumann, D.
Resource-aware IoT Control: Saving Communication through Predictive Triggering
IEEE Internet of Things Journal, 6(3):5013-5028, June 2019 (article)
Mager, F., Baumann, D., Jacob, R., Thiele, L., Trimpe, S., Zimmerling, M.
Feedback Control Goes Wireless: Guaranteed Stability over Low-power Multi-hop Networks
In Proceedings of the 10th ACM/IEEE International Conference on Cyber-Physical Systems, pages: 97-108, 10th ACM/IEEE International Conference on Cyber-Physical Systems, April 2019 (inproceedings)
Duecker, D. A., Geist, A. R., Kreuzer, E., Solowjow, E.
Learning Environmental Field Exploration with Computationally Constrained Underwater Robots: Gaussian Processes Meet Stochastic Optimal Control
Sensors, 19, 2019 (article)
2018
Baumann, D., Zhu, J., Martius, G., Trimpe, S.
Deep Reinforcement Learning for Event-Triggered Control
In Proceedings of the 57th IEEE International Conference on Decision and Control (CDC), pages: 943-950, 57th IEEE International Conference on Decision and Control (CDC), December 2018 (inproceedings)
Reeb, D., Doerr, A., Gerwinn, S., Rakitsch, B.
Learning Gaussian Processes by Minimizing PAC-Bayesian Generalization Bounds
In Proceedings Neural Information Processing Systems, Neural Information Processing Systems (NIPS) , December 2018 (inproceedings)
Solowjow, F., Mehrjou, A., Schölkopf, B., Trimpe, S.
Efficient Encoding of Dynamical Systems through Local Approximations
In Proceedings of the 57th IEEE International Conference on Decision and Control (CDC), pages: 6073 - 6079 , Miami, Fl, USA, December 2018 (inproceedings)

Lima, G. S., Bessa, W. M., Trimpe, S.
Depth Control of Underwater Robots using Sliding Modes and Gaussian Process Regression
In Proceeding of the 15th Latin American Robotics Symposium, João Pessoa, Brazil, 15th Latin American Robotics Symposium, November 2018 (inproceedings)
Rohr, A. V., Trimpe, S., Marco, A., Fischer, P., Palagi, S.
Gait learning for soft microrobots controlled by light fields
In International Conference on Intelligent Robots and Systems (IROS) 2018, pages: 6199-6206, Piscataway, NJ, USA, International Conference on Intelligent Robots and Systems 2018, October 2018 (inproceedings)
Soloperto, R., Müller, M. A., Trimpe, S., Allgöwer, F.
Learning-Based Robust Model Predictive Control with State-Dependent Uncertainty
In Proceedings of the IFAC Conference on Nonlinear Model Predictive Control (NMPC), Madison, Wisconsin, USA, 6th IFAC Conference on Nonlinear Model Predictive Control, August 2018 (inproceedings)
Hertneck, M., Koehler, J., Trimpe, S., Allgöwer, F.
Learning an Approximate Model Predictive Controller with Guarantees
IEEE Control Systems Letters, 2(3):543-548, July 2018 (article)